Keyword [Cerebral Cortex] [CNN Limitation]
1. 大脑皮层微柱
- 人的大脑皮层厚度为3~4mm,包含28x10^9神经元和相同数量胶质细胞。纵向垂直于皮层表面的细胞组织成微柱,穿越II-VI层,形成一个个结构功能单元。
- 灵长类的微柱包含80~100个神经元,形成30~50mm直径,深度2~4mm的柱状结构。
- 在视觉区的纹状皮层,每个柱内神经元数目大约200~250个。十个左右微柱组成一个功能柱。因此,一个功能柱直径大约300~600mm。不同物种的脑容量相差很大(10^3),但功能柱大小接近。
- 芒卡斯尔认为功能柱是大脑皮层的基本的结构和功能单元,他有时也把它称为一个微型组件(module).
2. Max Pooling
Max pooling丢弃固定大小感知域中(nm-1)/nm的信息。随着层级的增加不断进行max pooling操作,相当于逐步增加感知区域,丢弃的范围逐步增大,丢弃的信息也不断增多,最终只有image整体中各object特征被激活,而位置信息(位置信息针对一些任务并不需要,如分类)被丢弃。
3. CNN局限性
Capsule Networks Are Shaking up AI — Here’s How to Use Them
Capsule Networks Explained
3.1. 不具有平移同变性
CNN具有translation invariant (平移不变性), 无论如何平移图像中的obj,都能检测到。不变性是通过Pooling下采样实现。但CNN不具有translation equivariance (平移同变性), 无法检测到obj平移的距离方向等变化,即。

由于CNN无法识别各sub-obj之间的相对位置关系,以致下图都被识别为Face。

CNNs work by accumulating sets of features at each layer. It starts of by finding edges, then shapes, then actual objects. However, the spatial relationship information of all these features is lost. 导致下图均被识别为peroson.

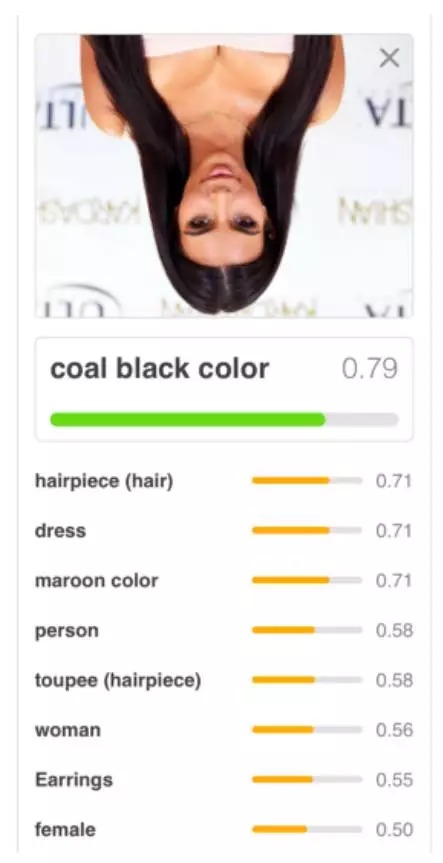
CNN is also easily confused when viewing an image in a different orientation. 下图被识别为coal black color.
CNN与CapsuleNet在识别上图人脸的区别
- CNN

- CapsuleNet

3.2. 易受白盒对抗攻击
3.3. 需要大量数据进行泛化
In order for the ConvNets to be translation invariant, it has to learn different filters for each different viewpoints, and in doing so it requires a lot of data.
3.4. CNN无法很好地表示人类视觉系统
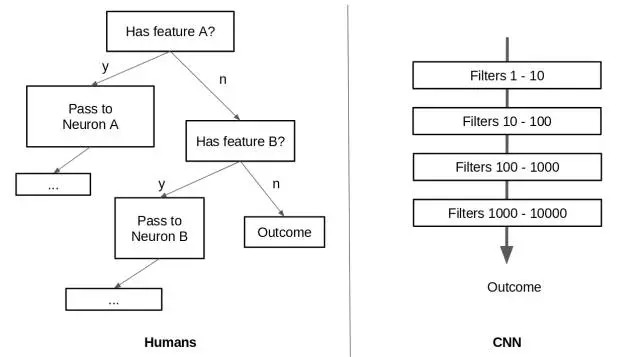
CNN利用filter从low level visual data提取high level information. 而对于人类系统而言,当触发视觉刺激时,大脑的内建机制会将low level visual data route到大脑某些部分。
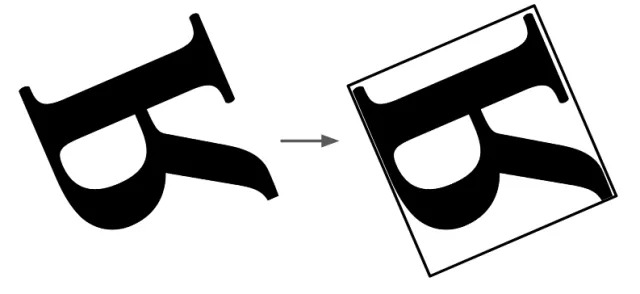
此外,人类视觉系统会对obj建立coordinate frames,并选择一个参考点,旋转obj.
4. ConvNet与CapsuleNet区别
CapsuleNet (mimics the human vision system) strives for translation equivariance instead of translation invariance, allowing it to generalize to a greater degree from different view points with less training data.
5. Inverse Graphics
5.1. 图像渲染过程
To go from a mesh object onto pixels on a screen, it takes the pose of the whole object, and multiplies it by a transformation matrix. This outputs the pose of the object’s part in a lower dimension (2D).

## 5.2. 图像逆过程
lower dimension –> whole object

5.3. 权重矩阵
因此,可用权重矩阵表示两者之间的关系。这些权重是viewpoint invariant. Meaning that however much the pose of the part has changed we can get back the pose of the whole using the same matrix of weights.
利用reconstruction得到该权重矩阵
6. 矢量神经元
知乎: 如何看待Hinton的论文《Dynamic Routing Between Capsules》

7. Hinton对CNN的思考
7.1. 生物神经系统的思考
- 解剖学上并未发现神经系统存在反向传播及求导的结构。
- 神经系统具有分层结构,但层数不多。生物系统传导在ms量级,GPU在us量级,同步出现问题。
- 大脑皮层存在微柱结构(Cortical minicolumn),其内部含有上百个神经元,并存在内部分层结构,比NN的一层结构更为复杂。

7.2. 认知神经科学的思考
人会不自觉根据物体形状建立坐标框架(coordinate frame), 并通过对坐标框架旋转。
- 坐标框架的不同会影响人的认知。
- 坐标框架参与到物体识别过程中,识别过程手空间概念的支配。
- CNN不存在坐标框架。
Hinton提出猜想:物体与观察者之间的关系(如物体姿态),应该由一整套激活的神经元表示,而不是由单个神经元,或者一组粗编码(coarse-coded,一层中并没有经过精细地组织)的神经元表示。这样才能有效表达坐标框架的先验知识。
7.3. CNN的局限性
- 不变性
物体不随变化而变化。如空间不变性。 同变性
用变化矩阵进行转换后,物体表示依旧不变。是对物体内容的变换。CNN对旋转没有不变性。可采用数据增强方式达到旋转不变性。
- CNN的不变性通过Pooling实现。
- 平移和旋转不变性舍弃了坐标框架。
- 虽然CNN准确率高,但是最终目标应该是对内容的良好表示,从而达到理解内容。
8. Hinton提出的Capsule
8.1. Capsule需具备的性质
- 一层中具有复杂的内部结构。
- 能表达坐标框架
- 实现同变性
8.2. Capsule神经元
Capsule用一组神经元代表一个实体,仅且代表一个实体。
- 模长代表某个实体(物体或其一部分)出现的概率。
- 方向/位置代表实体的一般姿态(generalized pose),报货位置、方向、尺寸、速度、颜色等。
8.3. 视角变换矩阵
CapsuleNet用视角变换矩阵处理场景中两物体间的关联,不改变它们的相对关系。

8.4. 两种同变性
- 位置编码 (place-coded)
视觉中的内容位置发生较大变化,由不同Capsule表示其内容。 - 速率编码 (rate-coded)
视觉中的内容位置发生较小变化,由相同capsule表示其内容,但是内容有所改变。
高层的capsule有更广的域(domain),所以低层的place-coded信息到高层会变成rate-coded.